Removing fsync from our local storage engine
How we used pre-allocation, O_DIRECT, and an SSD-aware journal to keep our local storage engine's writes crash-consistent without fsync.
Most storage engines pay fsync somewhere on the durable write path. We built a narrowly scoped single-node KV storage engine that does not call fsync for PUT or DELETE. The design relies on fixed-size preallocated files, pre-zeroed extents, O_DIRECT writes, and a journal whose commits are aligned to the SSD’s atomic-write unit.
This is not a general argument against fsync. It works because our durability contract is narrower than POSIX file semantics, our deployments are SSD-only, and the engine owns allocation, journaling, and recovery. In a 4KB random-write benchmark on AWS i8g.2xlarge local NVMe, the engine reached 190,985 obj/s versus 116,041 obj/s for ext4 + O_DIRECT + fsync.
The cost of fsync
Let’s start with how object stores and databases handle fsync today. MinIO, in both single-node and distributed deployments, eventually writes to the local filesystem. Each PUT issues fdatasync or fsync on the data part and on xl.meta, flushing the file to the device. RocksDB’s WAL doesn’t sync by default. Applications that need crash-consistent semantics have to opt in. etcd is stricter: every Raft entry is fsynced on the way to disk, and the etcd paper calls this out as essential to Raft safety. Postgres fsyncs the WAL at commit and uses group commit to amortize per-commit latency. Kafka is the outlier. By default it doesn’t fsync on the write path at all and leans entirely on replication for durability. The trade-off there is that single-node data safety is weakened. Data inside the power-loss window can be lost, and the cluster’s replication factor becomes the only line of defense.
Getting fsync right is hard. Jepsen has surfaced fsync-related data-loss bugs in distributed systems many times. One recent example is NATS 2.12.1 losing data on the crash-recovery path (Jepsen NATS 2.12.1 analysis).
Correctness aside, fsync is also expensive to call. A single fsync on an SSD typically takes a few hundred microseconds to a couple of milliseconds. Flushing data from the page cache to the device is just one part of that. The unpredictable part is metadata. fsync doesn’t just sync the file’s data, it syncs every piece of metadata the file depends on: inode, extent map, all the way down to the filesystem journal commit. An fsync call that looks like it’s only touching a few KB can trigger an order of magnitude more I/O underneath.
Tail latency is even harder to control. Beyond the filesystem journal flush, the actual latency of any given fsync call also depends on concurrent I/O on the same device, the journal’s current commit progress, and the SSD’s GC activity. Any one of those can push latency several times above the median.
Why we built our own engine
The fsync cost above becomes painful because a filesystem-backed object path turns each durable write into a filesystem transaction: file data, inode state, directory entries, extent maps, and journal commits all become part of the critical path. If we wanted crash-consistent writes without paying that cost on every PUT, we had to move the write-ahead boundary out of the filesystem and into a storage engine we control.
That only works because our local engine is not a general-purpose solution. Our context narrows the design space considerably:
- The medium is SSD only. We don’t target HDDs.
- Values range from a few hundred bytes to a few hundred KB.
- Write semantics are operation-atomic. A write is either fully visible or fully invisible.
- The interface is a simple KV API.
Loosen any of these (add HDD support, POSIX compatibility, or richer KV semantics) and the design has to be rethought from scratch.
With those constraints, the off-the-shelf options still left us paying for the wrong abstraction. Going straight to the filesystem with fsync preserves the metadata bottleneck described above. LSM engines like LevelDB and RocksDB still depend on fsync for the WAL when applications need crash-consistent commits, and their compaction layer adds significant write amplification, which is a poor fit for hundred-KB values. We chose to build a single-node engine from scratch: space allocation, indexing, journaling, and recovery, all in-house.
Architecture overview
The engine has three components: index, journal, and data area.
The index maps keys to value locations and is mostly resident in memory. The journal records changes to the index and to the data area’s allocation state. It is the engine’s crash-consistency boundary. The data area holds the values, written under an engine-managed layout strategy. Both the journal and the data area live on the filesystem. Runtime writes avoid filesystem metadata changes through fixed pre-allocation and pre-zeroing, use O_DIRECT to bypass the page cache, and rely on the journal rules below for crash consistency.
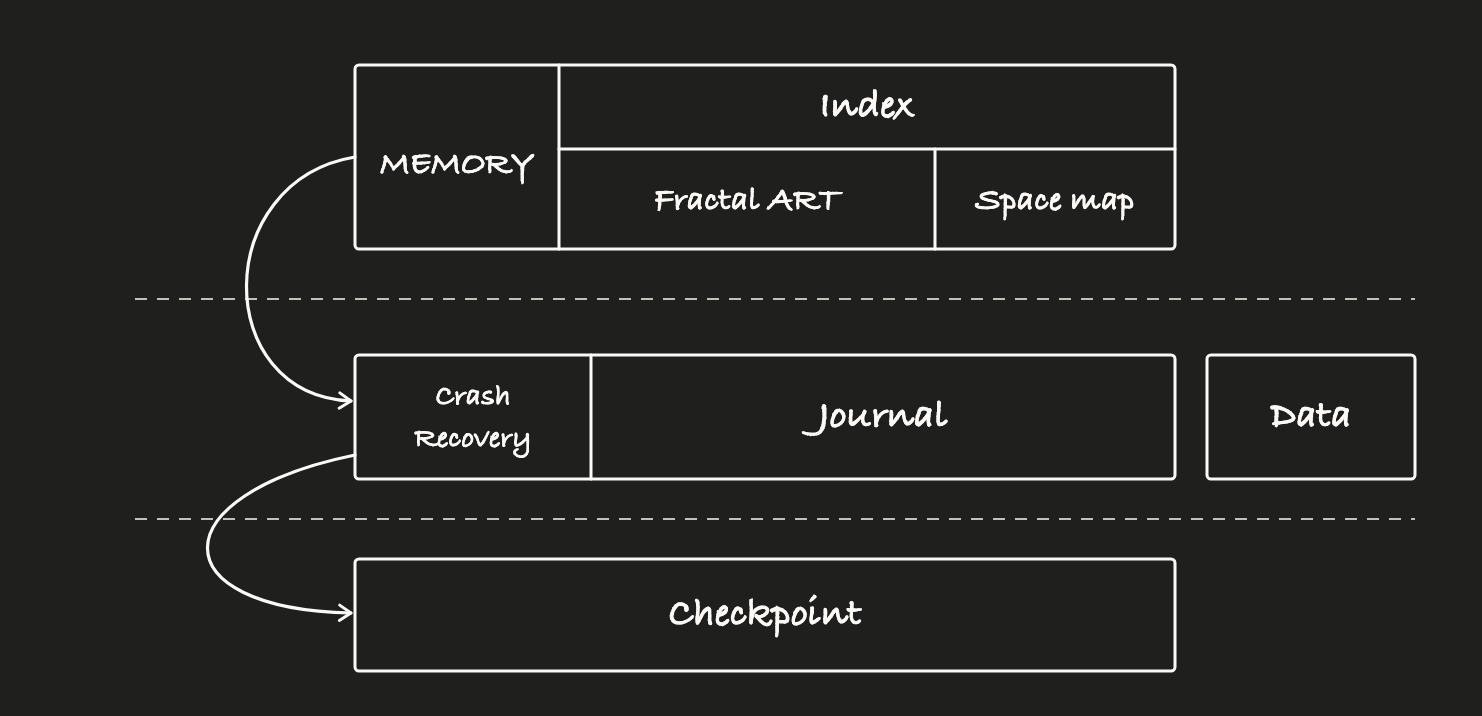
Index: single-node Fractal ART
The index maps keys to where their values live on disk. We didn’t build this from scratch. We reused our existing Fractal ART metadata engine and adapted it for the single-node case, mainly by adding journaling, checkpointing, and space management. The index aims to keep its data resident in memory but does not require a full upfront load. PUT and DELETE only modify in-memory pointers, which makes the operation atomic at the memory level. Persistence is delegated entirely to the journal.
Shared foundations
The journal area and the data area share two underlying design choices: fallocate-based pre-allocation and O_DIRECT writes.
Fixed-size pre-allocation. Both areas are pre-allocated with fallocate at startup, with sizes that stay fixed for the engine’s lifetime. This matters because if a file’s size grows on writes, the inode’s size field has to be updated, and a size change is metadata that requires fsync to make durable. Fixed sizing eliminates that path. Writes never allocate new extents and never modify file size. The inode stays unchanged. The write path never triggers filesystem-level metadata changes. There is one detail with fallocate (pre-zeroing) we’ll address later.
O_DIRECT writes. Both areas write through O_DIRECT with aligned buffers and offsets, bypassing the page cache. This removes the “dirty in kernel memory” intermediate state, so the engine does not need fsync merely to push cached pages down to the block layer.
O_DIRECT alone is not a universal durability guarantee. The no-fsync path depends on a storage contract: completed direct writes must not be sitting in an unprotected volatile cache, and 4KB-aligned journal writes must not tear across power loss. That is why our deployment target is cloud-provider local NVMe or enterprise NVMe with protected or nonvolatile cache behavior. If that contract is not true, the correct fallback is to reject no-fsync mode or use a sync-based path for the journal.
On NVMe SSDs that satisfy the contract, O_DIRECT also gives noticeably better tail-latency stability than buffered I/O because it removes page-cache writeback from the foreground write path.
Journal
The journal is the most sensitive part of the design. Most storage engines rely on fsync to make the WAL or journal durable, replaying it after a crash to recover a consistent state. Our goal is to preserve that “write completion equals persistence” guarantee without ever calling fsync.
The journal records only changes to the index and the space map. It does not carry value data. Value persistence is handled independently by the data area, and the journal only logs “where this key currently points.” Each record is typically tens to a couple hundred bytes, but the journal handles the engine’s highest-throughput writes and has the strictest latency and durability requirements.
Pre-allocation and O_DIRECT already eliminate the filesystem-layer uncertainty. To guarantee the integrity of a single record, the journal additionally relies on one device capability:
4KB atomic writes. For this design to be correct, the device/platform contract must guarantee that a 4KB-aligned journal commit block cannot be torn, including the power-fail case. In NVMe terms, the relevant limits are the atomic write unit values reported by the device. A commit block either takes effect entirely or doesn’t happen at all. Journal commits are written with 4KB alignment, so a power loss can only fall between two commit blocks, not inside one.
Pre-allocation, pre-zeroing, O_DIRECT, and 4KB atomic journal commits together give the journal the same practical crash-consistency role as a post-fsync WAL write in this deployment, without paying fsync’s runtime cost. Within that device contract, a confirmed journal commit is treated as durable across power failure. Outside that contract, no-fsync mode is unsafe.
The design also yields a useful property:
Batch commits. Multiple concurrent puts can be merged into a single I/O write to the journal, raising I/O efficiency and lowering per-put average latency.
The engine periodically takes a checkpoint of the in-memory metadata index, which lets older journal blocks be reclaimed. Checkpoints run concurrently with foreground writes. On restart, the engine loads the most recent checkpoint and replays the journal from there.
Recovery depends on the journal being self-describing and verifiable. Each commit block carries a checkpoint epoch, a monotonically increasing sequence number, length-delimited record payloads, and a checksum. On restart, the engine loads the newest valid checkpoint, scans aligned journal commit blocks in order, applies records while the checksum and sequence checks hold. Because each commit block is atomic under the device contract, recovery sees either the previous state or the next complete commit. Values written to the data area before a journal commit, but not referenced by replay, are reclaimed by the space-map scan.
Data area
The data area stores values. On top of the shared foundations, it solves two more problems: space allocation and value placement.
Space allocation is fully under engine control. We maintain a separate space map that records which regions are free, which are in use, and where each value lives. It is independent of the filesystem’s extent tree. The benefits:
- Predictable allocation cost. All space-map queries and updates happen in memory and never enter the filesystem metadata path. The per-put allocation cost is essentially negligible.
- Cheap delete and reuse. Freeing space only flips bits in the space map. There is no filesystem-level metadata reclamation, and the freed region is immediately available for reuse.
- Flexible placement policy. Hot/cold partitioning and size-tiered placement strategies can be tuned freely based on access patterns, with no dependency on the filesystem allocator.
A complete PUT
Wiring the three components together, a single PUT looks like this:
- The caller invokes put(key, value).
- The engine allocates space from the space map.
- The value is written to the data area via O_DIRECT.
- A change record is batched into a 4KB-aligned journal commit block, capturing the new location and the space-map update.
- The in-memory index (Fractal ART) is updated to point at the new location.
- The PUT returns success.
The whole flow makes no fsync calls. Atomicity falls entirely on step 4. A journal commit already on disk is visible after restart. A commit that wasn’t written, or whose verification fails, is ignored during recovery. Step 3 writes the value before the journal commit, so its validity hinges on step 4. If power fails between step 3 and step 4, the space-map scan on restart classifies that region as uncommitted, and the data is invisible to any external reader.
For comparison, a strict PUT on a filesystem requires more than one fsync. Calling fsync on the file’s fd alone doesn’t guarantee the file exists. The directory entry is metadata of the parent directory, and a separate fsync on the parent’s fd is needed for that to be durable. Without it, a freshly created file can vanish after a power loss. This POSIX requirement is rarely followed in practice. Our engine sidesteps the entire metadata class via pre-allocation and fixed sizing. The PUT path doesn’t fsync any file or any directory.
DELETE is much cheaper in this design. A delete record goes into the journal, the index drops the key, and the space map flags the region as reclaimable. The data area is never touched. The space the old value occupied is naturally reused on the next overwrite. On a filesystem, delete is the opposite. unlink touches the parent’s directory entry, the inode, and the extent records, with every change going through the filesystem journal. Even an implementation like MinIO that doesn’t fsync the parent after unlink still pays the metadata-commit cost. This is where the design buys back a lot of filesystem metadata cost.
There is a less obvious second-order effect on the filesystem side: deletes interfere with concurrent puts. Both operations contend for the same filesystem journal, so put tail latency takes a hit when deletes are concurrent. Deletes also fragment the free-extent structure, which forces subsequent puts to search through holes for usable regions. In our engine, delete only touches the in-memory space map, and put allocates from the same map. There is no shared metadata-I/O path between them.
A note on pre-zeroing
After fallocate, the journal and data areas need one more setup step: pre-zeroing the entire region.
fallocate only marks the extent as “allocated” at the filesystem layer. It doesn’t actually write data. On ext4 and XFS, this is called an unwritten extent. The first write into one of these regions triggers an extent conversion from unwritten to written, which updates inode metadata and commits to the filesystem journal. In other words, the benefit of pre-allocation is consumed on the first write.
We sidestep this by writing zeros across the entire region right after fallocate, forcing every extent into the written state. This is a one-time startup cost in exchange for never triggering filesystem-level metadata updates on the runtime write path. If extent conversion ever leaks into the runtime path, every previous effort to avoid metadata I/O is wasted, and the latency tail comes back.
Performance numbers
We benchmarked the engine against filesystem-based approaches under a 4KB random-write workload. Test environment: AWS EC2 i8g.2xlarge local NVMe SSD, 4KB files and values, ext4 for the filesystem baselines, single-threaded io_uring, queue depth QD=100. The benchmark is intentionally about the local write path, not the full distributed product stack.
4KB random write
| Configuration | Throughput (obj/s) | avg | P50 | P99 |
|---|---|---|---|---|
| ext4 + buffered + fsync | 79,123 | 1262 µs | 1229 µs | 1852 µs |
| ext4 + O_DIRECT + fsync | 116,041 | 859 µs | 828 µs | 1425 µs |
| Our engine | 190,985 | 413 µs | 363 µs | 1013 µs |
The engine’s throughput is 2.4× the buffered+fsync case and 1.6× the O_DIRECT+fsync case. Average latency is 3.1× and 2.1× lower respectively. The gap comes from removing fsync from the write path entirely, plus pre-allocation eliminating filesystem-journal metadata commits, which is what tightens the tail latencies.
A note on fairness: both ext4+fsync configurations only fsync the data file, not the parent directory. POSIX strictly requires a parent-directory fsync to make a newly created file’s existence durable. Otherwise the file can disappear after a power loss. So the two control configurations are weaker than strict POSIX durability for newly created files. Adding the parent-directory fsync would only make their latencies worse and widen the gap.
Known limitations
Requires a narrow SSD durability contract. The no-fsync path is only correct when direct-write completion and 4KB atomic journal-commit assumptions hold across power failure. Commodity SSDs, RAID layers, or unsafe write-back caches can break those assumptions. Those environments need an explicit sync-based fallback.
Not suited for HDDs. The optimization assumes SSD random-write performance is good enough. On HDDs, seek dominates, the space-map layout strategy needs a redesign, and O_DIRECT loses much of its advantage.
Not a general-purpose KV engine. The current API is narrowly scoped to what our product needs. PUT, GET, DELETE, and LIST cover our cases but don’t match general-purpose KV engines like RocksDB or LevelDB. Complex range-scan variants, TTL, secondary indexes, and compression-policy tuning are not implemented.
Not a general transaction engine. The engine does not try to provide arbitrary multi-statement database transactions, cross-table transactions, or serializable isolation. We are not a database and don’t intend to evolve into one. Workloads that need those semantics should use something else.
Still on a filesystem, not raw drive. fallocate plus pre-zeroing plus O_DIRECT minimizes filesystem-metadata noise on the write path, but we have not actually skipped the filesystem layer. For on-prem deployments where the workload can take a whole device, going further is a natural next step: dropping the filesystem entirely and managing the block layer directly. Direct raw-drive control allows tighter management of device-level write patterns, lower host-side write amplification reaching NAND, and better integration with host-managed features like ZNS to reduce in-drive GC. The result would be even more predictable latency.
Closing
Removing fsync was not a trick; it moved responsibility from the filesystem into our engine and deployment contract. In our high-performance setting, fsync’s cost was high enough to justify rebuilding the write path around explicit allocation, journaling, and recovery. The design is narrower than a filesystem or general-purpose database, but for this workload the performance numbers say the trade-off was worth it.